Convert NumPy array to Pandas DataFrame (15+ Scenarios)
Often we need to create data in NumPy arrays and convert them to DataFrame because we have to deal with Pandas methods.
In that case, converting the NumPy arrays (ndarrays) to DataFrame makes our data analyses convenient. In this tutorial, we will take a closer look at some of the common approaches we can use to convert the NumPy array to Pandas DataFrame.
We will also witness some common tricks to handle different NumPy array data structures having different values to Pandas DataFrame.
- 1 Creating NumPy arrays (ndarrays)
- 2 Converting homogenous NumPy array (ndarrays) using DataFrame constructor
- 3 Adding column name and index to the converted DataFrame
- 4 Converting heterogeneous NumPy array to DataFrame
- 5 Create DataFrame from NumPy array by columns
- 6 Create DataFrame from NumPy array by rows
- 7 Concatenate NumPy array to Pandas Dataframe
- 8 Append NumPy array as new column within DataFrame
- 9 NumPy array to DataFrame using concat()
- 10 Converting NumPy array to DataFrame using random.rand() and reshape()
- 11 Adding NumPy array to Pandas DataFrame using tolist()
- 12 Creating DataFrames thorugh np.zeros()
- 13 Creating DataFrames using random.choice() of NumPy array
- 14 Transpose a NumPy array before creating DataFrame
- 15 Creating empty DataFrame from an empty NumPy array
- 16 Generating DataFrame through iterations of NumPy arrays
Creating NumPy arrays (ndarrays)
NumPy arrays are multi-dimensional arrays, they can store homogenous or heterogeneous data.
There are different ways we can create a NumPy array.
Method 1: Using arange() method: It will create a range of values as per the given parameter, starting from zero. Here is a code snippet showing how to use it.
import numpy as np arry = np.arange(20) print(arry)
Output

This is one dimensional array.
Method 2: Using list and numpy.array(): In this technique, we will use the numpy.array() method and pass the list to convert it to an array. Here is a code snippet showing how to use it.
import numpy as np li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] arry = np.array(li) print(arry)
Output

But for DataFrame, we will need a two dimensional array. To create a two dimensional array, we have two different approaches:
Using the arange() and reshape(): We can use both these methods one after another to generate a range of values and place them in a proper shape. Here is a code snippet showing how to use it.
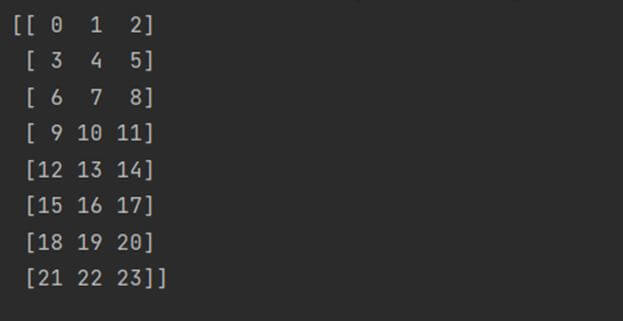
import numpy as np arry = np.arange(24).reshape(8,3) print(arry)
Output
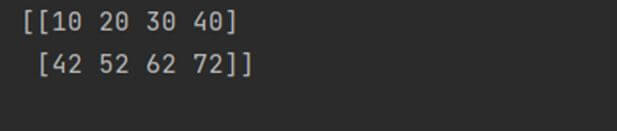
Using list and numpy.array(): In this technique, we will use the numpy.array() method and pass a nested list to convert it to an array. Here is a code snippet showing how to use it.
import numpy as np li = [[10, 20, 30, 40], [42, 52, 62, 72]] arry = np.array(li) print(arry)
Output
Converting homogenous NumPy array (ndarrays) using DataFrame constructor
A DataFrame in Pandas is a two-dimensional collection of data in rows and columns. It stores both homogenous and heterogeneous data.
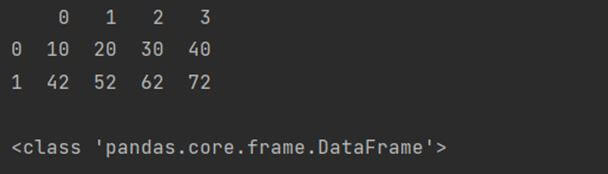
We have to use the DataFrame() constructor to create a DataFrame out of a NumPy array. Here is a code snippet showing how to use it.
import numpy as np import pandas as pd li = [[10, 20, 30, 40], [42, 52, 62, 72]] arry = np.array(li) dataf = pd.DataFrame(arry) print(dataf) print() print(type(dataf))
Output
Adding column name and index to the converted DataFrame
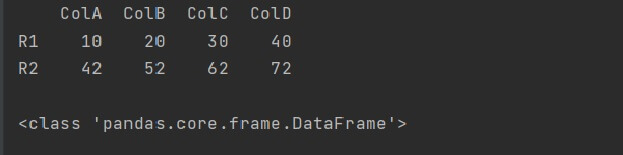
We can use the columns and index parameters in the DataFrame() to determine the column names and index labels to the DataFrame.
By default, the column and index value start from 0 and increment by 1. Here is an example of a DataFrame specifying the columns and index.
import numpy as np import pandas as pd li = [[10, 20, 30, 40], [42, 52, 62, 72]] arry = np.array(li) dataf = pd.DataFrame(arry, index = ['R1', 'R2'], columns = ['ColA', 'ColB', 'ColC', 'ColD']) print(dataf) print() print(type(dataf))
Output
Converting heterogeneous NumPy array to DataFrame
We can also create a DataFrame from a NumPy array that contains heterogeneous values as a nested list.
We can pass the ndarrays object to the DataFrame() constructor and set the column values to create a DataFrame with a heterogeneous data value.
Here is an example of a DataFrame with heterogeneous data.
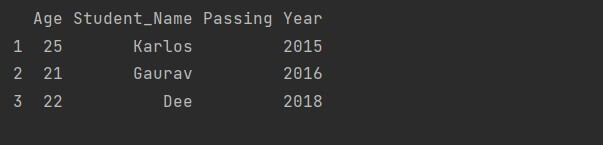
import numpy as np import pandas as pd arry = np.array([[25, 'Karlos', 2015], [21, 'Gaurav', 2016], [22, 'Dee', 2018]], dtype = object) df = pd.DataFrame(arry, columns = ['Age', 'Student_Name', 'Passing Year'] , index = [1, 2, 3]) print(df)
Output
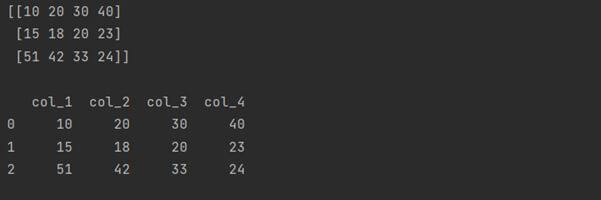
Create DataFrame from NumPy array by columns
This is another approach to create a DataFrame from NumPy array by using the two dimensional ndarrays column-wise thorough indexing mechanism.
It works similarly to that of column-major in general array. Here is an example showing how to use it.
import numpy as np
import pandas as pd
arry = np.array([[10, 20, 30, 40],
[15, 18, 20, 23],
[51, 42, 33, 24]])
print(arry, "\n")
myDat = pd.DataFrame({'col_1': arry[:, 0], # Create pandas DataFrame
'col_2': arry[:, 1],
'col_3': arry[:, 2],
'col_4': arry[:, 3]})
print(myDat)
Output
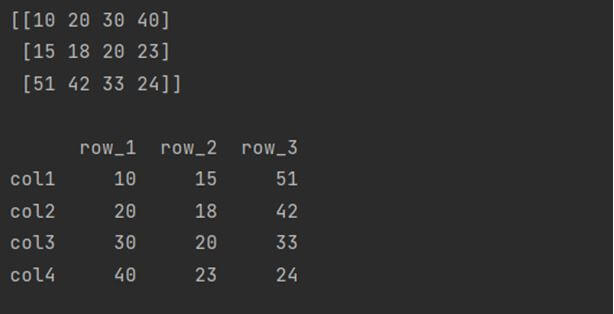
Create DataFrame from NumPy array by rows
This is another approach to create a DataFrame from NumPy array by using the two dimensional ndarrays row-wise thorough indexing mechanism. It works similarly to that of row-major in general array. Here is an example showing how to use it.
import numpy as np
import pandas as pd
arry = np.array([[10, 20, 30, 40],
[15, 18, 20, 23],
[51, 42, 33, 24]])
print(arry, "\n")
myDat = pd.DataFrame({'row_1': arry[0, :], # Create pandas DataFrame
'row_2': arry[1, :],
'row_3': arry[2, :]}, index = ['col1', 'col2', 'col3', 'col4'])
print(myDat)
Output
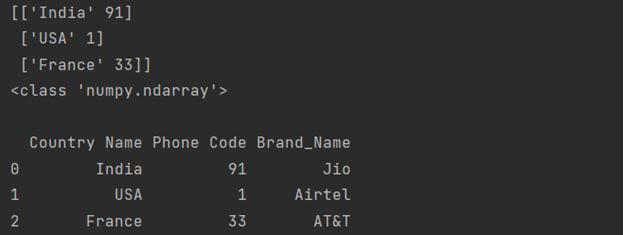
Concatenate NumPy array to Pandas Dataframe
We can also make concatenate NumPy arrays to Pandas DataFrame by creating one DataFrame (through ndarray) and merging it with the other using the equal operator. Here is a code snippet showing how to implement it.
import numpy as np import pandas as pd ary = np.array([['India', 91], ['USA', 1], ['France', 33]], dtype = object) print(ary) print(type(ary), "\n") df = pd.DataFrame(ary, columns = ['Country Name', 'Phone Code']) arr1 = np.array([['Jio'], ['Airtel'], ['AT&T']], dtype=object) df2 = pd.DataFrame(arr1, columns = ['Brand']) df['Brand_Name'] = df2['Brand'] print(df)
Output
Append NumPy array as new column within DataFrame
We can also directly incorporate a 2D NumPy array into a Pandas DataFrame. To do this, we have to convert a nested list to Pandas DataFrame and assign it to the existing DataFrame column with a column name.
Here is a code snippet showing how to append a new NumPy array-based column directly with a column name.
import numpy as np
import pandas as pd
df = pd.DataFrame(np.arange(4, 13).reshape(3, 3))
df['New_Col'] = pd.DataFrame(np.array([[2],
[4],
[6]]))
print(df)
Output
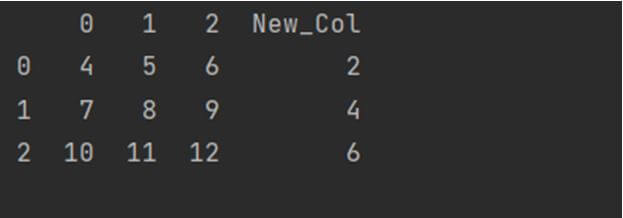
NumPy array to DataFrame using concat()
The concat() is another powerful method of Pandas to concatenate two DataFrame into a new one. We can use the concat() method to concatenate a new DataFrame with a NumPy array.
Its syntax will be: pandas.concat([dataframe1, pandas.DataFrame(ndarray)], axis = 1) Here is the code snippet showing how to implement it.
import numpy as np
import pandas as pd
df = pd.DataFrame({'value1': [25, 12, 15, 14, 19],
'value2': [52, 17, 12, 9, 41],
'value3': [10, 30, 15, 11, 14]})
newArr = np.matrix([[12, 13],
[11, 10],
[22, 17],
[18, 27],
[31, 14]])
new_df = pd.concat([df, pd.DataFrame(newArr)], axis = 1)
print(new_df)
Output
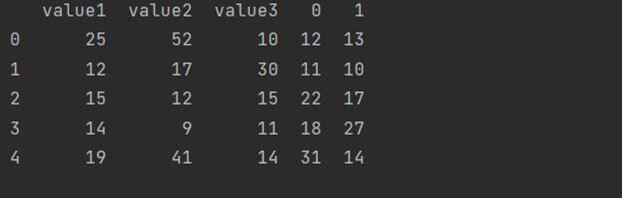
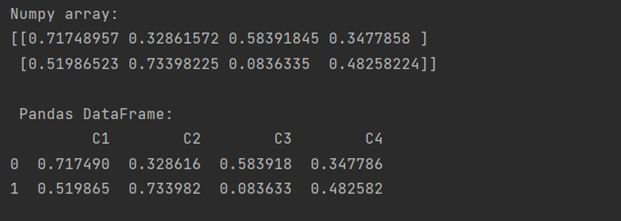
Converting NumPy array to DataFrame using random.rand() and reshape()
We can generate some random numbers (using random.rand()) and reshape the entire object in a two-dimensional NumPy array format using the reshape().
Then we can convert it to a DataFrame. Here is a code snippet showing how to implement it.
import numpy as np
import pandas as pd
arry = np.random.rand(8).reshape(2, 4)
print("Numpy array:")
print(arry)
# convert numpy array to dataframe
df = pd.DataFrame(arry, columns = ['C1', 'C2', 'C3', 'C4'])
print("\n Pandas DataFrame: ")
print(df)
Output
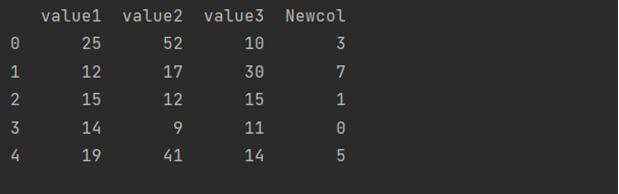
Adding NumPy array to Pandas DataFrame using tolist()
We can also use the NumPy’s tolist() method to fetch an entire NumPy array and place it as a part of the DataFrame column.
The syntax looks like: dataframe_object[‘column_name’] = ndarray_object.tolist() Here is a code snippet showing how to use it.
import numpy as np
import pandas as pd
df = pd.DataFrame({'value1': [25, 12, 15, 14, 19],
'value2': [52, 17, 12, 9, 41],
'value3': [10, 30, 15, 11, 14]})
new = np.array([3, 7, 1, 0, 5])
df['Newcol'] = new.tolist()
print(df)
Output
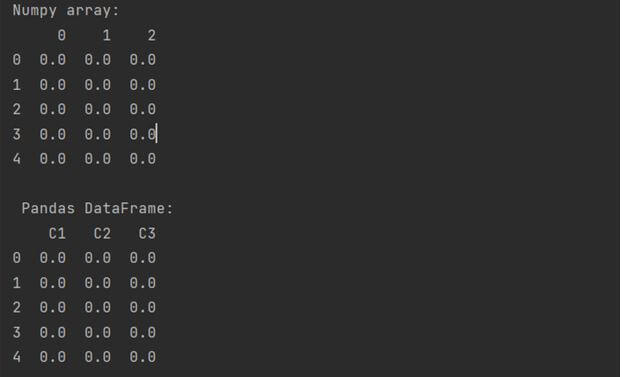
Creating DataFrames thorugh np.zeros()
We can also create a DataFrame by implementing the numpy.zeros(). Such ndarrays will have all zero values and will use the same for creating the DataFrame also.
Here is a code snippet showing how to implement it.
import numpy as np
import pandas as pd
arry = pd.DataFrame(np.zeros((5, 3)))
print("Numpy array:")
print(arry)
df = pd.DataFrame(arry, columns = ['C1', 'C2', 'C3'])
df = df.fillna(0)
print("\n Pandas DataFrame: ")
print(df)
Output
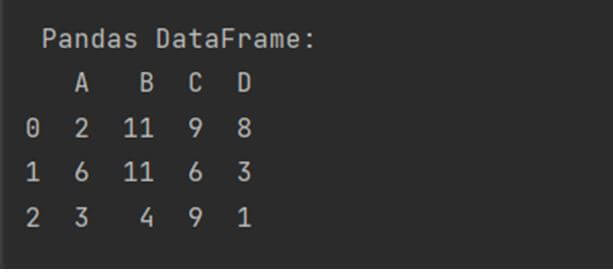
Creating DataFrames using random.choice() of NumPy array
Another way to create a NumPy array from a DataFrame is by using the random.choice() and placing it within the DataFrame() constructor to directly convert the NumPy array of a specific size to DataFrame. Here is a script showing how to implement it.
import numpy as np
import pandas as pd
df = df = pd.DataFrame(np.random.choice(12, (3, 4)), columns = list('ABCD'))
print("\n Pandas DataFrame: ")
print(df)
Output
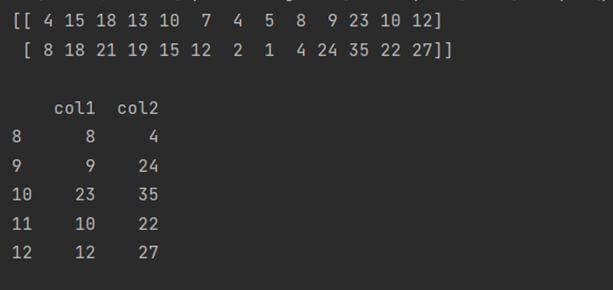
Transpose a NumPy array before creating DataFrame
We can create a transpose of a NumPy array and place it within a DataFrame. Here is a code example showing how to implement it.
import numpy as np
import pandas as pd
arry = np.array([[4, 8], [15, 18], [18, 21], [13, 19],
[10, 15], [7, 12], [4, 2], [5, 1], [8, 4], [9, 24],
[23, 35], [10, 22], [12, 27]])
arry_tp = arry.transpose()
print(arry_tp)
print()
df = pd.DataFrame({'col1': arry_tp[0], 'col2': arry_tp[1]})
print(df.tail())
Output
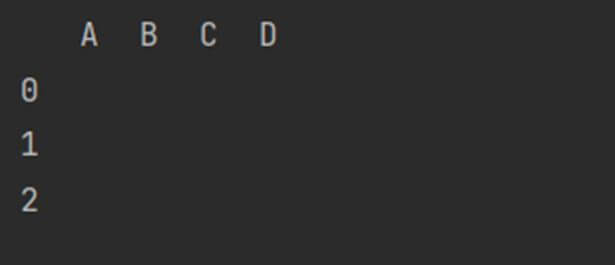
Creating empty DataFrame from an empty NumPy array
We can create an empty DataFrame from a NumPy array that stores NaN (Not a Number) values. Here is a code snippet showing how to implement it.
import pandas as pd
import numpy as np
df = pd.DataFrame(np.nan, index = [0, 1, 2], columns = ['A', 'B', 'C', 'D'])
df = df.fillna(' ')
print(df)
Output
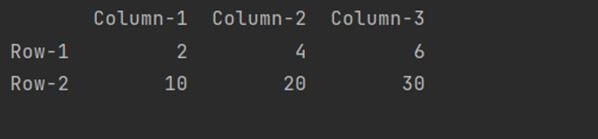
Generating DataFrame through iterations of NumPy arrays
We can run an implicit iteration like a list comprehension within the DataFrame() constructor that can leverage the NumPy array to iterate over the ndarray elements based on shape().
It can ultimately provide us a DataFrame from the ndarray. Here is a script showing how to perform it.
import pandas as pd
import numpy as np
arry = np.array([[2, 4, 6],
[10, 20, 30]])
df = pd.DataFrame(data = arry[0:, 0:],
index = ['Row-' + str(g + 1)
for g in range(arry.shape[0])],
columns=['Column-' + str(g + 1)
for g in range(arry.shape[1]) ])
print(df)
Output
Gaurav is a Full-stack (Sr.) Tech Content Engineer (6.5 years exp.) & has a sumptuous passion for curating articles, blogs, e-books, tutorials, infographics, and other web content. Apart from that, he is into security research and found bugs for many govt. & private firms across the globe. He has authored two books and contributed to more than 500+ articles and blogs. He is a Computer Science trainer and loves to spend time with efficient programming, data science, Information privacy, and SEO. Apart from writing, he loves to play foosball, read novels, and dance.