30 Examples for Awk Command in Text Processing
The awk command or GNU awk in specific provides a scripting language for text processing. With awk scripting language, you can make the following:
- Define variables.
- Use string and arithmetic operators.
- Use control flow and loops.
- Generate formatted reports.
Actually, you can process log files that contain maybe millions of lines to output a readable report that you can benefit from.
- 1 Awk Options
- 2 Read AWK Scripts
- 3 Using Variables
- 4 Using Multiple Commands
- 5 Reading The Script From a File
- 6 Awk Preprocessing
- 7 Awk Postprocessing
- 8 Built-in Variables
- 9 More Variables
- 10 User Defined Variables
- 11 Structured Commands
- 12 Formatted Printing
- 13 Built-In Functions
- 14 String Functions
- 15 User Defined Functions
Awk Options
The awk command is used like this:
$ awk options program file
Awk can take the following options:
-F fs To specify a file separator.
-f file To specify a file that contains awk script.
-v var=value To declare a variable.
We will see how to process files and print results using awk.
Read AWK Scripts
To define an awk script, use braces surrounded by single quotation marks like this:
$ awk '{print "Welcome to awk command tutorial "}'

If you type anything, it returns the same welcome string we provide.
To terminate the program, press The Ctrl+D. Looks tricky, don’t panic, the best is yet to come.
Using Variables
With awk, you can process text files. Awk assigns some variables for each data field found:
- $0 for the whole line.
- $1 for the first field.
- $2 for the second field.
- $n for the nth field.
The whitespace character like space or tab is the default separator between fields in awk.
Check this example and see how awk processes it:
$ awk '{print $1}' myfile
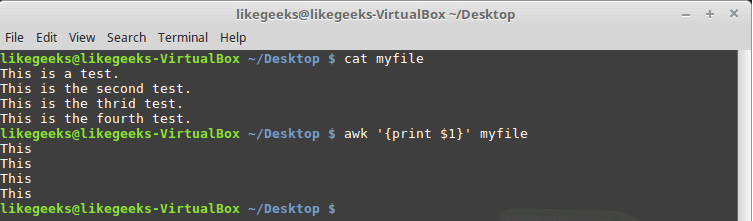
The above example prints the first word of each line.
Sometimes the separator in some files is not space nor tab but something else. You can specify it using –F option:
$ awk -F: '{print $1}' /etc/passwd
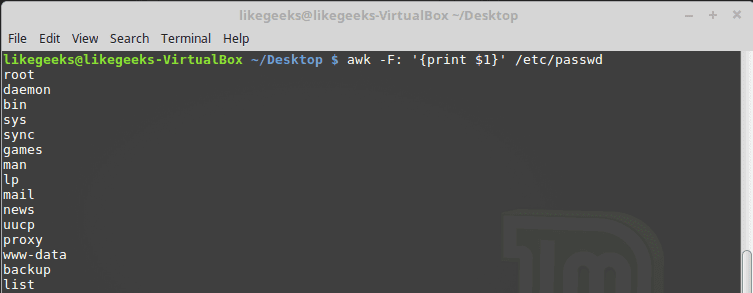
This command prints the first field in the passwd file. We use the colon as a separator because the passwd file uses it.
Using Multiple Commands
To run multiple commands, separate them with a semicolon like this:
$ echo "Hello Tom" | awk '{$2="Adam"; print $0}'

The first command makes the $2 field equals Adam. The second command prints the entire line.
Reading The Script From a File
You can type your awk script in a file and specify that file using the -f option.
Our file contains this script:
{print $1 " home at " $6}
$ awk -F: -f testfile /etc/passwd
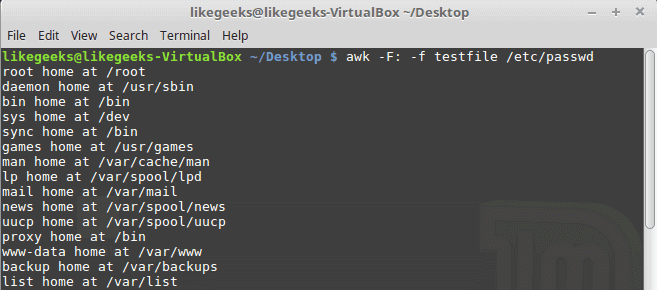
Here we print the username and his home path from /etc/passwd, and surely the separator is specified with capital -F which is the colon.
You can your awk script file like this:
{
text = $1 " home at " $6
print text
}
$ awk -F: -f testfile /etc/passwd
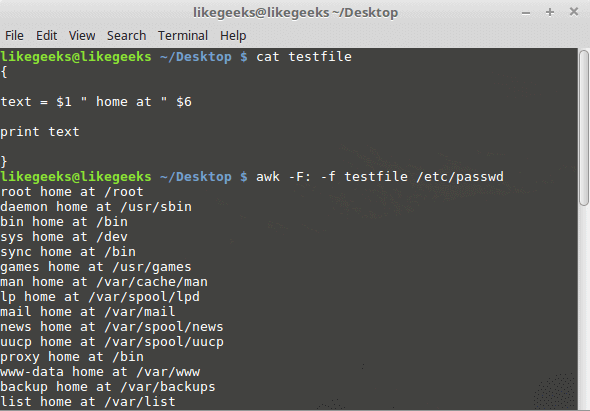
Awk Preprocessing
If you need to create a title or a header for your result or so. You can use the BEGIN keyword to achieve this. It runs before processing the data:
$ awk 'BEGIN {print "Report Title"}'
Let’s apply it to something we can see the result:
$ awk 'BEGIN {print "The File Contents:"}
{print $0}' myfile
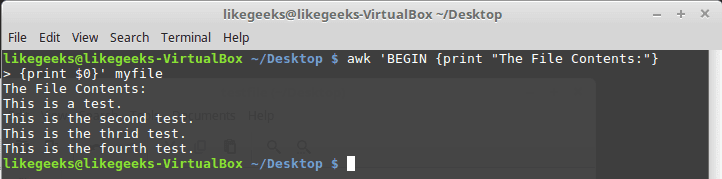
Awk Postprocessing
To run a script after processing the data, use the END keyword:
$ awk 'BEGIN {print "The File Contents:"}
{print $0}
END {print "File footer"}' myfile
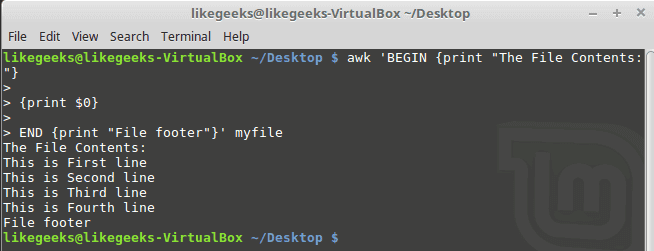
This is useful, you can use it to add a footer for example.
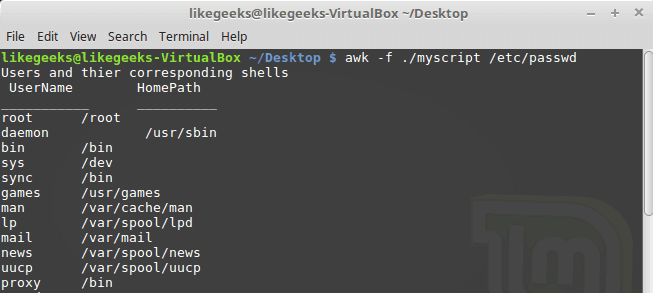
Let’s combine them together in a script file:
BEGIN {
print "Users and thier corresponding home"
print " UserName \t HomePath"
print "___________ \t __________"
FS=":"
}
{
print $1 " \t " $6
}
END {
print "The end"
}
First, the top section is created using BEGIN keyword. Then we define the FS and print the footer at the end.
$ awk -f myscript /etc/passwd
Built-in Variables
We saw the data field variables $1, $2 $3, etc are used to extract data fields, we also deal with the field separator FS.
But these are not the only variables, there are more built-in variables.
The following list shows some of the built-in variables:
FIELDWIDTHS Specifies the field width.
RS Specifies the record separator.
FS Specifies the field separator.
OFS Specifies the Output separator.
ORS Specifies the Output separator.
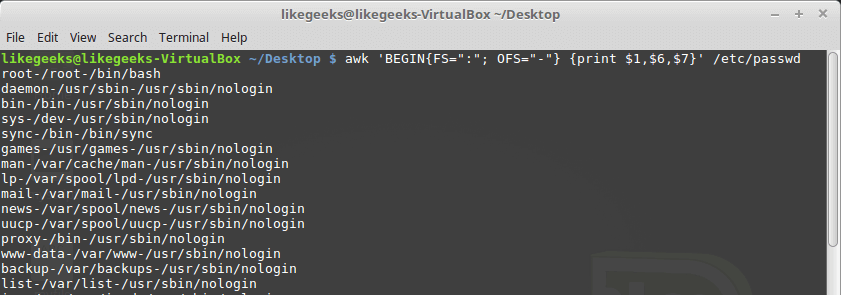
By default, the OFS variable is the space, you can set the OFS variable to specify the separator you need:
$ awk 'BEGIN{FS=":"; OFS="-"} {print $1,$6,$7}' /etc/passwd
Sometimes, the fields are distributed without a fixed separator. In these cases, FIELDWIDTHS variable solves the problem.
Suppose we have this content:
1235.96521 927-8.3652 36257.8157
$ awk 'BEGIN{FIELDWIDTHS="3 4 3"}{print $1,$2,$3}' testfile
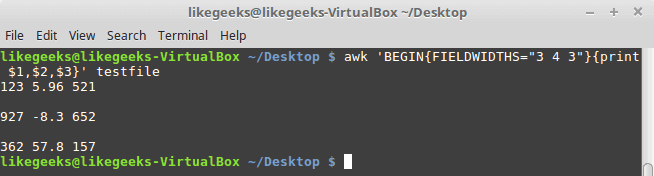
Look at the output. The output fields are 3 per line and each field length is based on what we assigned by FIELDWIDTH exactly.
Suppose that your data are distributed on different lines like the following:
Person Name 123 High Street (222) 466-1234 Another person 487 High Street (523) 643-8754
In the above example, awk fails to process fields properly because the fields are separated by newlines and not spaces.
You need to set the FS to the newline (\n) and the RS to a blank text, so empty lines will be considered separators.
$ awk 'BEGIN{FS="\n"; RS=""} {print $1,$3}' addresses
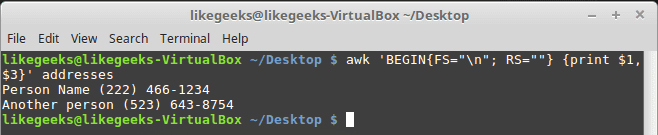
Awesome! we can read the records and fields properly.
More Variables
There are some other variables that help you to get more information:
ARGC Retrieves the number of passed parameters.
ARGV Retrieves the command line parameters.
ENVIRON Array of the shell environment variables and corresponding values.
FILENAME The file name that is processed by awk.
NF Fields count of the line being processed.
NR Retrieves total count of processed records.
FNR The record which is processed.
IGNORECASE To ignore the character case.
Let’s test them.
$ awk 'BEGIN{print ARGC,ARGV[1]}' myfile

The ENVIRON variable retrieves the shell environment variables like this:
$ awk '
BEGIN{
print ENVIRON["PATH"]
}'
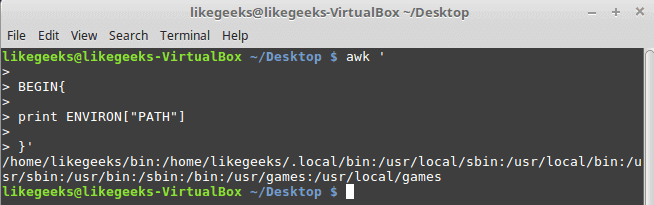
You can use bash variables without ENVIRON variables like this:
$ echo | awk -v home=$HOME '{print "My home is " home}'

The NF variable specifies the last field in the record without knowing its position:
$ awk 'BEGIN{FS=":"; OFS=":"} {print $1,$NF}' /etc/passwd
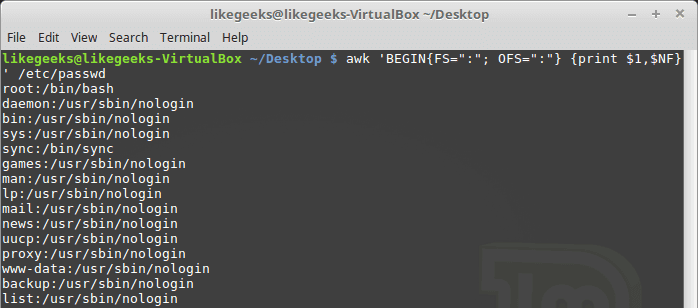
The NF variable can be used as a data field variable if you type it like this: $NF.
Let’s take a look at these two examples to know the difference between FNR and NR variables:
$ awk 'BEGIN{FS=","}{print $1,"FNR="FNR}' myfile myfile
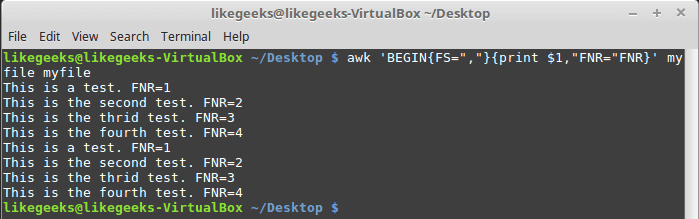
In this example, the awk command defines two input files. The same file, but processed twice. The output is the first field value and the FNR variable.
Now, check the NR variable and see the difference:
$ awk '
BEGIN {FS=","}
{print $1,"FNR="FNR,"NR="NR}
END{print "Total",NR,"processed lines"}' myfile myfile
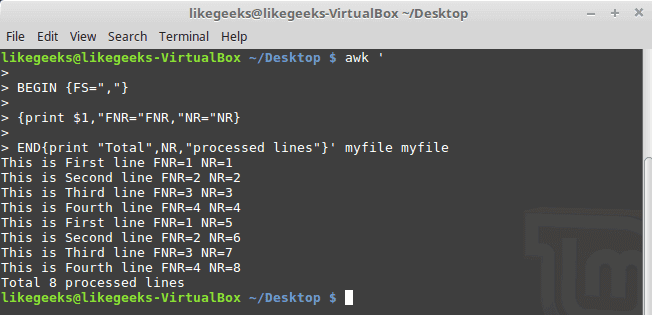
The FNR variable becomes 1 when comes to the second file, but the NR variable keeps its value.
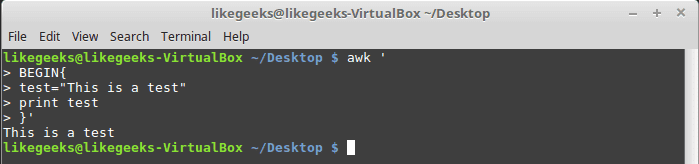
User Defined Variables
Variable names could be anything, but it can’t begin with a number.
You can assign a variable as in shell scripting like this:
$ awk '
BEGIN{
test="Welcome to LikeGeeks website"
print test
}'
Structured Commands
The awk scripting language supports if conditional statement.
The testfile contains the following:
10
15
6
33
45
$ awk '{if ($1 > 30) print $1}' testfile

Just that simple.
You should use braces if you want to run multiple statements:
$ awk '{
if ($1 > 30)
{
x = $1 * 3
print x
}
}' testfile
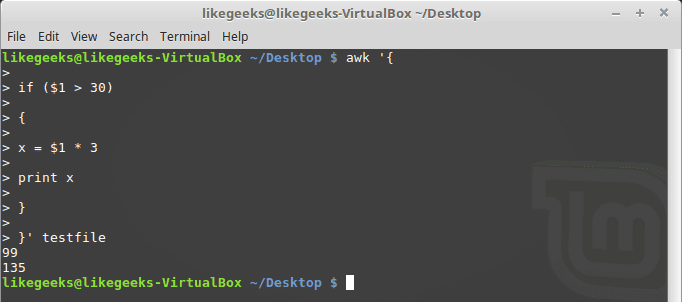
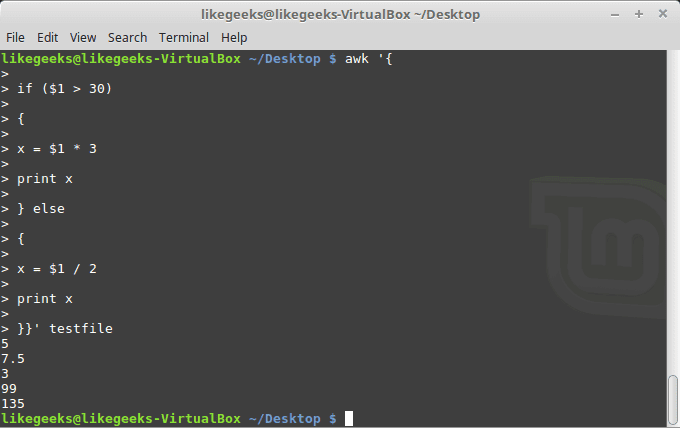
You can use else statements like this:
$ awk '{
if ($1 > 30)
{
x = $1 * 3
print x
} else
{
x = $1 / 2
print x
}}' testfile
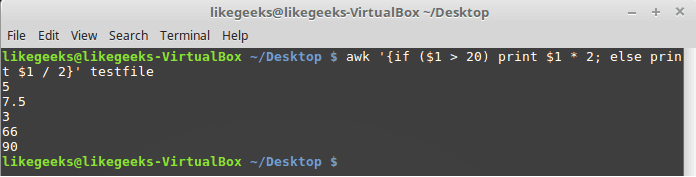
Or type them on the same line and separate the if statement with a semicolon like this:
While Loop
You can use the while loop to iterate over data with a condition.
cat myfile
124 127 130
112 142 135
175 158 245
118 231 147
$ awk '{
sum = 0
i = 1
while (i < 5)
{
sum += $i
i++
}
average = sum / 3
print "Average:",average
}' testfile
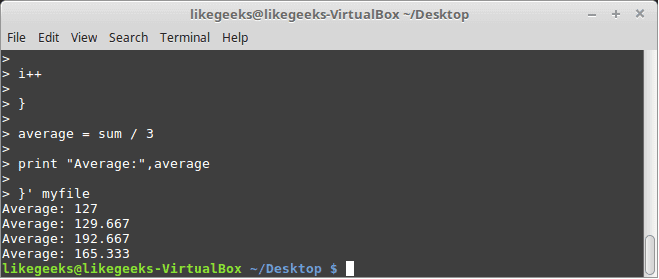
The while loop runs and every time it adds 1 to the sum variable until the i variable becomes 4.
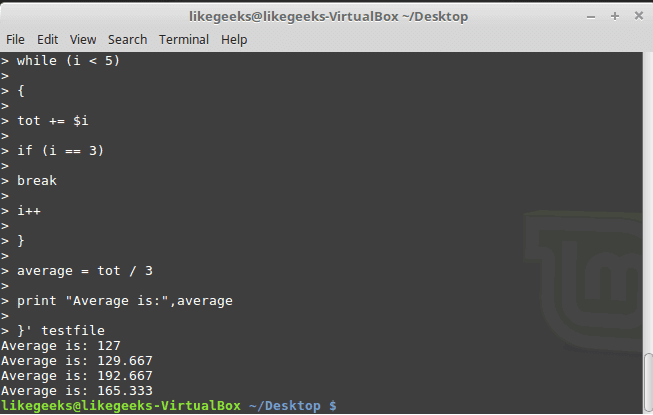
You can exit the loop using break command like this:
$ awk '{
tot = 0
i = 1
while (i < 5)
{
tot += $i
if (i == 3)
break
i++
}
average = tot / 3
print "Average is:",average
}' testfile
The for Loop
The awk scripting language supports the for loops:
$ awk '{
total = 0
for (var = 1; var < 5; var++)
{
total += $var
}
avg = total / 3
print "Average:",avg
}' testfile
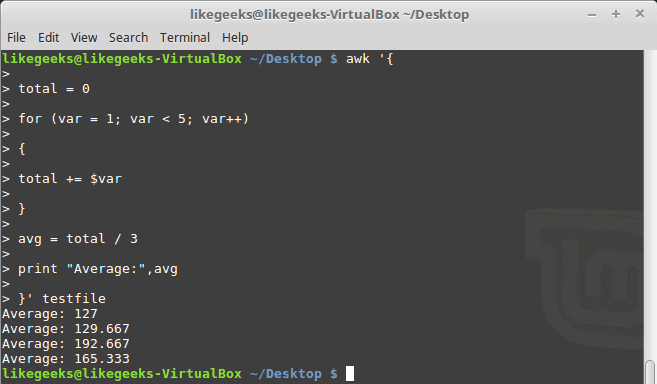
Formatted Printing
The printf command in awk allows you to print formatted output using format specifiers.
The format specifiers are written like this:
%[modifier]control-letter
This list shows the format specifiers you can use with printf:
c Prints numeric output as a string.
d Prints an integer value.
e Prints scientific numbers.
f Prints float values.
o Prints an octal value.
s Prints a text string.
Here we use printf to format our output:
$ awk 'BEGIN{
x = 100 * 100
printf "The result is: %e\n", x
}'
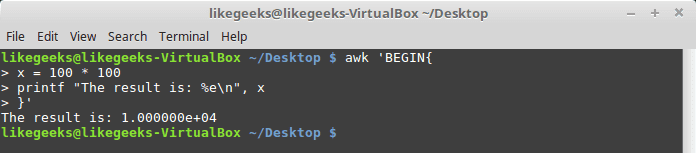
Here is an example of printing scientific numbers.
We are not going to try every format specifier. You know the concept.
Built-In Functions
Awk provides several built-in functions like:
Mathematical Functions
If you love math, you can use these functions in your awk scripts:
sin(x) | cos(x) | sqrt(x) | exp(x) | log(x) | rand()
And they can be used normally:
$ awk 'BEGIN{x=exp(5); print x}'

String Functions
There are many string functions, you can check the list, but we will examine one of them as an example and the rest is the same:
$ awk 'BEGIN{x = "likegeeks"; print toupper(x)}'

The function toupper converts character case to upper case for the passed string.
User Defined Functions
You can define your function and use them like this:
$ awk '
function myfunc()
{
printf "The user %s has home path at %s\n", $1,$6
}
BEGIN{FS=":"}
{
myfunc()
}' /etc/passwd
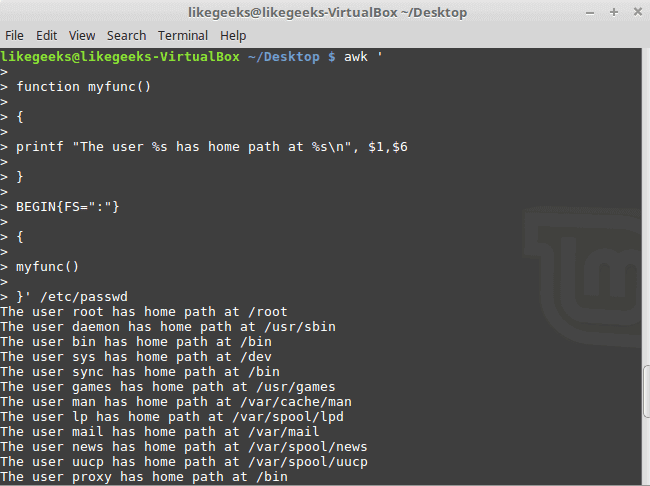
Here we define a function called myprint, then we use it in our script to print output using printf function.
I hope you like the post.
Thank you.
Mokhtar is the founder of LikeGeeks.com. He is a seasoned technologist and accomplished author, with expertise in Linux system administration and Python development. Since 2010, Mokhtar has built an impressive career, transitioning from system administration to Python development in 2015. His work spans large corporations to freelance clients around the globe. Alongside his technical work, Mokhtar has authored some insightful books in his field. Known for his innovative solutions, meticulous attention to detail, and high-quality work, Mokhtar continually seeks new challenges within the dynamic field of technology.
I can’t get the output shown on the first terminal screen shot. Is the command correct?
edit. I get it now. Sorry for disturbing in the comments 😀
You have to hit ENTER. Awk won’t print that per the instructions.
No problem, you are welcome all the time.
Regards,
I’d like to suggest one correction, if I may. I got a little confused with the NF built-in variable, which made me read the man page for awk, and I think the NF built-in holds the “total number of fields in the ‘current input record’ ” and not ‘data file’. That made me confused a little.
Thanks for the work!
Thank you very much Amani for your notice, appreciate it.
Can I also suggest a correction ?
>>>>>>>>
$ echo “Hello Tom” | awk ‘{$4=”Adam”; print $0}’
awk multiple commands
The first command makes the $2 field equals Adam. The second command prints the entire line.
>>>>>>>>
The command to make $2 field equal to Adam should be awk ‘{$2=”Adam”; print $0}’
Thanks!! and sorry for the typo.
Great Tutorial 🙂 Please add more examples.
Thank you very much. I’ll add more soon.
I don’t typically engage in the comments section of any website I visit, but I just had to say thank you for such an exceptionally well-written tutorial. I had initially set out to try to find someone else’s solution to a problem I was having, but after reading this I was able to figure out what I had been doing wrong to begin with.
I’m very happy with that.
Thanks for the kind words and have wonderful rest of the weekend!
Ideally the example for awk while break program for average should run not more than 3 but in your example/output it runs more than thrice.
Thanks for your comment!
Actually, it runs 3 times only and the code breaks when the i variable equals 3 and this happens for the four lines of the file.
hello, i need help with command bash
i want this ouput :
Aug 05 08:54:52 Installed: perl-XML-Simple-2.14-4.fc6.noarch
Aug 05 08:57:10 Installed: yum-utils-1.1.16-21.el5.centos.noarch
Aug 05 14:59:19 Installed: libgcc-4.1.2-55.el5.i386
Aug 05 14:59:19 Installed: libstdc++-4.1.2-55.el5.i386
Aug 05 14:59:24 Installed: ncurses-5.5-24.20060715.i386
Aug 05 14:59:25 Installed: mysql-5.0.95-5.el5_9.i386
Aug 05 14:59:26 Installed: mysql-server-5.0.95-5.el5_9.i386
i try command : cat /var/log/yum.log | awk ‘{ print $1, $2, $3 } print ‘Aug 05”
but not work, with based on date, can you help me with correct command?
Thanks.
Based on the date, you can write the following
awk '/Aug 05/ { print $0 }' /var/log/yum.logRunning script using file has correction. kindly change that one.
Thanks!
Done.
Great explained! I’ll use awk now for sure.
Thanks!
Awk is awesome and simple if we get used to it.
Great tutorial! It motivates me to learn awk.
Question:
How would I use awk to calculate the sum of columns of numbers?
My text file looks like this:
2019/04/03 150100 150105 Store
2019/04/04 150210 150239 Gym
2019/04/05 151290 151303 Friend’s house
How could I use awk (or other tools) to find the total number of miles driven?
Pretty easy!
To calculate the sum of the second column, you can do it like this:
$ awk '{sum+=$2;}END{print sum;}' myfileHope that helps.
Very well explained… Thanks
Thank you very much!
Thank you for answering my earlier question. Your tip worked perfectly!
Is it possible to use awk (or other linux tools) to sum columns only when they match a condition? For example, I have 2 cars I use for business travel. I want to calculate the total miles driven for Car 1 and for Car 2. Is there a way to do this ?
Sample data file:
Car1 2019/04/03 150100 150105 Store
Car 2 2019/04/04 150210 150239 Gym
Car 1 2019/04/05 151290 151303 Friend’s house
Could I generate a statement like “total mileage for this month is 5 miles for Car 1 and 15 miles for Car 2” ?
Also easy!
just state your condition before you calculate the sum.
$ awk '{if($1=="Car1" || $1=="Car2" ) sum+=$3;}END{print sum;}' myfileThis will caculate the total of Car1 and Car2.
Now you can write your own condition based on your needs.
Regards,
Hi! I have a question:
How am I supposed to get the sum of only numeric values in a string?
For example:
If I have a string ‘ABC1234’, ‘DEF5678′,’ and I only need to take the sum of the numeric values (1234 +5678)
Thank you!
You can extract numeric values from any string using awk like this:
$ echo 'ABC1234' | awk -F'[^0-9]*' '$0=$2'Also, you can use grep which is a bit favorite in extracting things!
$ echo 'ABC1234', 'DEF5678' | grep -o '[0-9]\+'Then you can do anything with the extracted numbers.
Thank you very much, Mr. Mokhtar Ebrahim.
I have text to process but difficult to post it here. I will appreciate if I can contact you on your email.
Thank you in advance.
You can write a pattern of your text if it follows a specific pattern.
Nice
Thanks!
Best awk tutorial for quick learning. Great job.
Thank you very much!
Much appreciated for the effort and your follow up with every single reply, keep the great work!
Thank you very much! I’ll do my best.
Hi.. I am looking for a solution for extracting info from a text file.. the file is as follows
VFUNC 4718 2020 770951 3187699
0 2052
25 2300
50 2512
100 2930
VFUNC 4718 2040 770979 3187750
0 2056
25 2302
50 2530
100 2950
My aim is to extract the 4th and 5th value from the 1st row containing 5 values and attached those values in front of the rows containing only 2 values.. my result should look like this
770951 3187699 0 2052
770951 3187699 25 2300
770951 3187699 50 2512
770951 3187699 100 2930
770979 3187750 0 2056
770979 3187750 25 2302
770979 3187750 50 2530
770979 3187750 100 2950
Any help is highly appreciated
This code will do what you want
NR==1 { f4=$4 f5=$5 } NR>1 && NR<6{ print f4 " " f5 " " $0 } NR>6 && NR<11{ print f4 " " f5 " " $0 }First, we get the fourth and fifth fields of the first row.
Then, we bind them at the beginning of the next rows starting from the second row.
Regards,
Mokhtar.. thanks.. I’ll give it a try.. cheers
You’re welcome!
Good luck.
Mokhtar.. thanks for the help.. I was wondering how do I extend the previous code.. where I need to extract the 4th and 5th value from every nth row and concatenate those values to the rows n+1 to 2n-1.. I know you have to do a nested for loop.. I am not a programmer so any help would be appreciated. I mean to say I need to extract the 4th and 5th value from 1st row and attach it to row 2-5.. then extract the 4th and 5th value from 6th row attach it to 7-11 row and repeat the same for a large file.. Thanks for your help.. cheers
You can use the for loops as discussed on the tutorial and iterate over your lines the same way.
Hi..
Great tutorial.
I am looking for a solution for this dimensions in pixels from multipage pdf file to count pages of size A4,A3,A2,A1,A0.
Supose A4= 100 pixels
Example output is in pixels of every page:
10×10
5×10
20×10
30×10
30×30
50×50
……
Each line number of column multiply eg. 10*10 and then divide by A4=100.
To this point I can do this by
awk ‘{ print ($1 * $2)/100 }’
but then is hard for me:
IF less than 1 that page is A4
if grater than 1 but less than 2 then A3
if grater than 2 but less than 4 then A2
if grater than 4 but less than 8 then A1
if grater than 8 but less than 16 then A0
Output will be sum every file page format:
A4 5
A3 2
A2 etc…
help is highly appreciated.
Thanks a lot.
Regarding your hard part, you can use if statements and increment the count for each if statement to get the total count of every page size.
Let’s assume you have the dimensions on a variable called x.
if(x < 1) { a4 += 1 } else if (x > 1 && x < 2) { a3 += 1 } else if (x > 2 && x < 4) { a2 += 1 } else if (x > 4 && x < 8) { a1 += 1 } else if (x > 8 && x < 16) { a0 += 1 } print "Total A4 pages: :",a4 print "Total A3 pages: :",a3 print "Total A2 pages: :",a2 print "Total A1 pages: :",a1 print "Total A0 pages: :",a0Hope that helps!
Thanks
That helps a lot.
My best…
You’re welcome! Thanks!
Hi, I am not a programmer at all. But, i am in a middle of my studies trying to convert some awk script to python for my projects. I wonder if you can help me
These are two different languages.
You can share what lines stop you and we will try to help as much as we can.
Regards,
Hi Mokhtar,
This is very informative. Thanks!
Can you help me with the below?
My file contains:
scirck-vccn059/properties/intgservername.txt.INCRHEAP.PRD:TransportationEventAgent 2048 2048
scirck-vccn060/properties/agentservername.txt.INCRHEAP.PRD:SyncExportPurgeAgent 512 512
scirck-vccn060/properties/agentservername.txt.INCRHEAP.PRD:ReleaseServer 2048 2048
I want below output:
scirck-vccn059,TransportationEventAgent
scirck-vccn060,SyncExportPurgeAgent
scirck-vccn060,ReleaseServer
Can you help me please?
Thanks!
You’re welcome!
You can specify all separators you want in the FS and then set the OFS to set the comma in the output:
$ awk ' BEGIN {FS="/|:| "; OFS=","} {print $1,$4}' myfileRegards,
Awesome. Thank you Mokhtar!
You’re welcome! Thanks!
Hello,
Ihave a scenario where i have multiple files(more than 100) such as
NEW_ABC0999.xyz06.d121719.t191923
NEW_ABC0999.XYZ06.d121419.t192038
i wanted to read only the first record of each file and add “0” at the end of first record of each file and update the file.
Input file
cat NEW_ABC0999.xyz06.d121719.t191923
C01~0000000390~MI999~16~31-DEC-19~AMIPS~2219~17-DEC-19~
M03~MI9991912170000000001~DQB~EI~3340000018322~P323B634~SP2183133~-000000001.0000~EA~
M03~MI9991912170000000002~DQB~EI~3340000018322~P323B634~SP2183133~-000000001.0000~EA~
expected output shouldbe
C01~0000000390~MI999~16~31-DEC-19~AMIPS~2219~17-DEC-19~0
M03~MI9991912170000000001~DQB~EI~3340000018322~P323B634~SP2183133~-000000001.0000~EA~
M03~MI9991912170000000002~DQB~EI~3340000018322~P323B634~SP2183133~-000000001.0000~EA~
Hi,
I think you should use sed than using awk.
Regards,
Thank you
You’re welcome!
Thanks,
regard by
kk
You’re welcome!
Tried them all. Helpful thank you. One example yields a different result than shown. Puzzled..
robert@claire2:~/computer/awk$ more addressesMultiLines.txt
Person Name
123 High Street
(222) 466-1234
Another person
487 High Street
(523) 643-8754
robert@claire2:~/computer/awk$ awk ‘BEGIN{FS=”\n”; RS=””} {print $1,$3}’ addressesMultiLines.txt
Person Name
123 High Street
(222) 466-1234
Another person
487 High Street
(523) 643-8754
robert@claire2:~/computer/awk$ awk ‘BEGIN{FS=”\n”; ORS=””} {print $1,$3}’ addressesMultiLines.txt
Person Name 123 High Street (222) 466-1234 Another person 487 High Street (523) 643-8754 robert@claire2:~/computer/awk$
The code syntax highlighter adds extra new line which is not needed in our example.
I updated the sample data. Now everything should works as expected.
Regards,
Duh yes! I propose that you incorporate more features in your for loop example which is the last of your control flow examples so the solution is more generic. Beem wanting to learn awk now I have some competencies with it. Regards
awk ‘{
total = 0
for (var = 0; var 0)
{
avg = total / NF
print “Average:”,avg
}
}’ myfile02
Cost pasting kinda broken trying one last time..
awk ‘{
total = 0
for (var = 0; var 0)
{
avg = total / NF
print “Average:”,avg
}
}’ myfile02
The for loop should be written like this:
for (var = 1; var < 5; var++) { total += $var }Hi how do i add my query here .Tried posting a query.But it didn’t show up on this page.
For below Code there is issue with alignment
Can u please help with below Query:
Input file used:
123213123; 321321331231123213213213213213213232323323232123223; 3233; kartuhalo bebas; 2020-18-20; 2020-18-20; 1; 3; 2020; 23213; 3123; 321312; 321321; 32121; 321321; 333333333
3123213123; 23213213213; 3233; kartuhelo abnomen; 2020-18-20; 2020-18-20; 1; 3; 2020; 242; 4324242342; 434; 321321; 32121; 4444; 33333432
123213123; 32132133123112321321321321321321323232332; 3233; kartuhalo bebas; 2020-18-20; 2020-18-20; 1; 3; 2020; 23213; 3123; 321312; 321321; 32121; 321321; 333333333
123213123; 321321331231123213213213213213213232323323232123223; 3233; kartuhalo bebas; 2020-18-20; 2020-18-20; 1; 3; 2020; 23213; 3123; 321312; 321321; 32121; 321321; 333333333
123213123; 32132133123112321321321321321321323232332323223; 3233; kartuhalo bebas; 2020-18-20; 2020-18-20; 1; 3; 2020; 23213; 3123; 321312; 321321; 32121; 321321; 333333333
123213123; 3213213312311232132132132132123223; 3233; kartuhalo bebas; 2020-18-20; 2020-18-20; 1; 3; 2020; 23213; 3123; 321312; 321321; 32121; 321321; 333333333
Code:
echo “Enter File name”
read file_name
echo “—————————————————INV Extract Mapped———————————————————————–”
awk -F “;” -v cols=”BA ID; MSISDN; SOC ID; SOC Name; SOC Effective Date; SOC Termination Date; Cycle Code; Cycle Month; Cycle Year; RC Charges; Discounted RC Charges; OC Charges; Discounted OC Charges; Tiered RC Charges; Tiered Discount; Split Bill Charges” ‘
BEGIN {
col_count=split(cols, col_arr, “;”);
for (i=1; i<=col_count; i++) printf col_arr[i] ((i==col_count) ? "\n" : "\t");
}'
awk -F ";" '
{
for (i=1; i<=NF; i++) printf $i ((i==NF) ? "\n" : "\t");
}' $file_name
Hi,
The alignment looks correct, but I think that the second field in the first row makes it bigger for your screen resolution to appear aligned.
Is there any way to provide a common fieldwidth for all columns.
FIELDWIDTH attributes needs width to be specified to each field .Didn’t know how to give common fieldwidth to all fields in input file
Hai.. Thanks for this awesome tutorial..
Can I get ur help to solve my issue..
I am given 3 columns empid,name and salary separated by ‘;’ each.
I need to output the name of the employee who has the maximum salary..
I also need to know how to store two separate columns from the command line input (not input file) in two separate arrays.
Thanks in Advance 🙂
You’re welcome!
Regarding the first question, you can use sort command to sort the third column numerically and in reverse order so you can get the highest value on the top.
Then you can pipe it to the head command to get the first row only.
Finally, you can use awk to print the third column which is the salary in our case.
$ sort -nrk3 -t ';' myfile | head -1 | awk 'BEGIN { FS = ";" } ; { print $3 }'Regarding the second question, can you specify the input exactly?
Regards,
Using awk, how would I create a script that scans a file with names, calculates how many names start with or contain a specific letter, and then prints a line with the total number of names containing that letter?
Hi,
You can use the index function which return zero if nothing is found and non zero is someting is found and then add them to a variable to sum the count:
$awk ‘BEGIN{RS=”[[:space:][:punct:]]”; c=0} index($0,”a”){c++} END{print c}’ myfile
Regards,
can i cearte a water bill with awk language ???
AWK is a powerful scripting language in text processing.
You can do a lot with it.
Hi Mokhtar,
Great tutorial to get the basics.
However, I am not able to write a code in bash to find if the two input integer numbers are Amicable or not?
could you help me with this?
Hi,
Can you share what you wrote so we can help you?
I have question for one example.
Hi Tina,
Drop your question here and we’ll try to help.
hello Mokhtar
i have below record
cellid=10
TA=10
TA=5
cellid=20
TA=3
TA=50
TA=100
and it want to be shown like below:
cellid=10, TA=10,TA=5
cellid=20,TA=3,TA=50,TA=100
appreciated to help
Hi Farid,
You can split each group of lines into separate files like this:
$ awk '/cellid=[0-9]/{line="group"++i;}{print > line;}' testbased on the current content, this will create 2 files called group1 and group2.
Each file will contain the lines under it.
Hope that helps!
hi mokhtar
i was makes a sales.txt :
$cat sales.txt
FIRZA
2222
78
84
77
MIMI
5555
56
58
45
how i can make a script RS awk with output like this:
$ awk -f sales.awk sales.txt
FIRZA 2222
MIMI 5555
then, how to makes a script using NR so the output will be like this :
1 FIRZA 2222 78 84 77
2 MIMI 5555 56 58 45
Hi,
You can extract each group into a separate file like this:
$ awk '/[A-Z]/{line="group"++i;}{print > line;}' testRegards,
Hi Mokhtar,
I am new to awk and found your tutorial extremely helpful. Thank you. Does awk have an if conditional statement with syntax to identify file extensions ?
I have extracted a list of filenames from a floppy disk image
grep Sounddsk2.img ls -a1 > allfilenames
This creates a list like this
flute.co
flute.pt
flute.ss
flute.vc
guitar.co
guitar.pt
guitar.ss
guitar.vc
Does awk have a string function that will allow me to extract a list of only the filenames ending in .ss ?
e.g. by doing something like this
gawk ‘{ if ($1+”.ss” is true) print $1}’ allfilenames > ssfilenames
Hi Greg,
You can use if statement to check for file extension like this:
$ awk -F, ‘$1 ~ /\.ss$/ {print $1}’
This will print all lines end with ss extension.
Regards,
File contains below rows and coulmns. I need for every row how many coulmns are available.
1,Bhargav,560,Khammam,Telangana
2,Srinu
3,Pandu,890
4,Prudhvi,780,Hyderabad
OUTPUT :
First Row – 5 columns
Second Row – 2 Columns
Third Row – 3 Columns
Fourth Row – 4 Columns
Could you please help me here
We can get the number of columns by getting the fields count like this:
$ awk --field-separator="," '{print "row"$1 " " NF}' myfileHi Mokhtar,
great tutorial!
I’m just starting out with awk, I would like to know if I can use the FIELDWIDTHS command to format my columns. When I use awk ‘{print $ ….} to try to display my columns, I find this:
my file.dat | awk ‘{FIELDWIDTHS=”,,,”} {print $..,$.,$..}’ > newfile.dat
Region Lat Long
ARABIA-W 27.080 37.250
34.500 131.600 571
-23.300 -67.620 6046
14.501 -90.876 3976
Columns mix with other unselected columns
The desired result is this:
Region lat long elevation
ARABIA-W 27.080 37.250 1900
HONSHU-JAPAN 34.500 131.600 571
CHILE-N -23.300 -67.620 6046
GUATEMALA 14.501 -90.876 3976
Can you help me please because i want to use latitudes and longitudes
Hi,
You didn’t mention your input data.
However, the FIELDWIDTHS is a list of field widths separated by a space.
Ex:
FIELDWIDTHS=”4 5 7 6″
You can use this in case your field are not the same such as:
1111
11111
1111111
111111
Regards,
Hello Mokhtar,
pleease help to get this:
cellid=10
TA=10
TA=5
cellid=20
TA=3
TA=50
TA=100
You can split each group of lines into separate files like this:
$ awk ‘/cellid=[0-9]/{line=”group”++i;}{print > line;}’ test
based on the current content, this will create 2 files called group1 and group2.
Each file will contain the lines under it.
As I understand /cellid=[0-9]/ will match only cellid=1 or cellid=2 from above record, why does awk command provided by you places the whole group (cellid=10\nTA=10\nTA=5) to the file???
THANKS A LOT for this and for your posts, they are cooool, thanks again
Hi,
The command splits each group and place it in a separate file.
So group1 file contains:
cellid=10
TA=10
TA=5
And group2 file contains:
cellid=20
TA=3
TA=50
TA=100
The awk command only stops when it sees the matched text ‘/cellid=[0-9]/ otherwise, it will continue through the lines.
Please help me in proving the script that retrieves the contents of the particular path in the below JSON output
[{“path”:”lam/kej/bat.p12″,”data”:{“type”:”FILE”,”description”:”new p12 file”,”dfsxcvxc”:null,”contents”:”dHlwZT1qZjdskdjskdjskfjskfhbWU9YWlrX29wZF9wb3BlCnBhc3
N3b3JkPWNuZHZqZHZqdgpkcml2ZXJjbGFzcz1wsdsdsdsdsdsdsdsddsssfsdfsfdsfsdfsffdfddssfdsfsdfsffsfsG5qZW5qdi5jb20KbWF4eHRvdGFsPTIzMAptYXh3YWl0bWlsbHM9MjkwMDA=”},”owner”:”fdsf
sfdfs”,”recipients”:[{“value”:”fdfff_vfd_polk_poik”}],”metadata”:{“createdby”:”nhjdnd”,”createdts”:”12-22-0940 20:09:34″,”lastupdatedby”:”vffsfsfs”,”lastupdatedby”:”09
-34-9989 09:44:23″,”version”:8,”active”:true},”delegates”:[{“value”:”bifd_fdd_fdff_jdj@oppd.fdjfjdj.net”},{“value”:”dndhdj”},{“value”:”vdvdvd”},{“value”:”dndhdj”},{“va
lue”:”vdvdvd”}]”env”:”dev”,”orgid”:”nan”,”family”:”kkf”,”adp”:”cdfvdvdv”,”targetorgid”:null,”requester”:null,”dpprocessid”:null,”gamodjitg”:””,”subtype”:”db”,”selected”
:false,”dmx”:false,”komprefix”:null,”gamouser”:false},{“path”:”lam/kej/purpose.p12″,”data”:{“type”:”FILE”,”description”:”new purpose file”,”dfsxcvxc”:null,”contents”:”fs
fsZzfdfdfdfssfsfLmZqZmoKdXNlcm5hbWU9YWlrX29wZF9wb3BlCnBhc3N3b3JkPWNuZHZqZHZqdgpkcml2ZXJjbGFzcz1wb2N2ZmQuZmp2ai5mZnJmdnYKdXJsPWpmZWtmLmdlZ2QuZmVnZmVnQG5qZW5qdi5jb20KbWF4
eHRvdGFsPTIzMAptYXh3YWl0bWlsbHM9MjkwMDA=”},”owner”:”2ndsfsfdfs”,”recipients”:[{“value”:”2nd_vfd_polk_poik”}],”metadata”:{“createdby”:”2ndjdnd”,”createdts”:”12-22-0940
20:09:34″,”lastupdatedby”:”2ndfsfsfs”,”lastupdatedby”:”09-34-9989 09:44:23″,”version”:8,”active”:true},”delegates”:[{“value”:”2ndfd_fdd_fdff_jdj@oppd.fdjfjdj.net”},{“va
lue”:”2nddhdj”},{“value”:”2ndvdvd”},{“value”:”2nddhdj”},{“value”:”2ndvdvd”}]”env”:”mit”,”orgid”:”nan”,”family”:”2nd”,”adp”:”2nddv”,”targetorgid”:null,”requester”:null,”
2ndrocessid”:null,”g2ndodjitg”:””,”subtype”:”db”,”selected”:false,”dmx”:false,”2ndprefix”:null,”gamouser”:false}]
Hi,
You didn’t mention if you want a specific part of the JSON path or the entire part.
Can you tell us what command did you ran and results did you got?
Regards,
Hi
I have input file like
0000000001YYICA1Pi prk werrr
0000000001YYICA20001
0000000001YYICA3CBA0000 100
0000000001YYICA4NEU
0000000001YYICA5
0000000001YYICA6 20231102
0000000001YYICA1Pi prk werrr
0000000001YYICA20001
0000000001YYICA3KLM0000 100
0000000001YYICA4NEU
0000000001YYICA5
0000000001YYICA6 20231102
0000000001YYICA1Pi prk werrr
0000000001YYICA20001
0000000001YYICA3ABV0000 100
0000000001YYICA4NEU
0000000001YYICA5
0000000001YYICA6 20231102
but i want output like
0000000001YYICA1Pi prk werrr
0000000001YYICA20001
0000000001YYICA3CBA0000 100
0000000001YYICA4NEU
0000000001YYICA5
0000000001YYICA6 20231102
0000000002YYICA1Pi prk werrr
0000000002YYICA20001
0000000002YYICA3KLM0000 100
0000000002YYICA4NEU
0000000002YYICA5
0000000002YYICA6 20231102
0000000003YYICA1Pi prk werrr
0000000003YYICA20001
0000000003YYICA3ABV0000 100
0000000003YYICA4NEU
0000000003YYICA5
0000000003YYICA6 20231102
here Every 6 lines from column 1 to 10 should be unique and next 6 lines should be +1 means create sequence number in unix
thank ou
Hi,
You can write a script that increments a counter every six lines and then substitutes the first 10 characters of each line with the incremented value.
awk '{ if (NR % 6 == 1) counter++; printf "%010d%s\n", counter, substr($0, 11); }' input_file.txt > output_file.txtHope that helps!
I Have files like
abcd_200003001.act
abcd_200003002.act
abcd_200003003.act
abcd_200003004.act
I need to count Incrementally and display and compare with previous file only +1 file need to display else come out from loop
Hi,
You can use the following awk script:
ls abcd_*.act | awk -F_ '{print $2}' | sort -n | awk '{ if (prev + 1 != $1) { print "File missing: abcd_" prev + 1 ".act"; exit; } prev = $1; }'The second awk command processes the sorted numbers and compares each number with the previous one.
If the current number is not exactly 1 greater than the previous number, it prints a message indicating the missing file and exits the loop.
Hope you find what you need!
Regards,
Hi,
I have this file :
RP/0/RSP0/CPU0:EBR-KDI.1#sho clock
Mon Jun 24 08:03:24.177 WITA
08:03:24.375 WITA Mon Jun 24 2024
RP/0/RSP0/CPU0:EBR-KDI.1#ping 36.95.255.73 source 36.95.255.74 rep 100
Mon Jun 24 08:03:24.628 WITA
Type escape sequence to abort.
Sending 100, 100-byte ICMP Echos to 36.95.255.73, timeout is 2 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Success rate is 100 percent (100/100), round-trip min/avg/max = 35/35/36 ms
RP/0/RSP0/CPU0:EBR-KDI.1#show bgp ipv6 unicast neighbor 2001:4488:702:5::1 detail | include state
Mon Jun 24 08:03:35.313 WITA
BGP state = Established, up for 2d14h
RP/0/RSP0/CPU0:EBR-KDI.1#show ospf neighbor bundle-ether 12.2900
Mon Jun 24 08:03:36.232 WITA
Neighbor ID Pri State Dead Time Address Interface
182.5.0.2 1 FULL/ – 00:00:34 182.5.0.66 Bundle-Ether12.2900
And need this output :
Mon Jun 10 08:24 WITA
#IPv4_EBRKDI.1-PE.TRANSIT.BAL=100 percent|35 ms
#BGP.IPv6=Established
#OSPF=FULL
Could you help me on this?
Hi,
From the output you need and input file I got the pattern and I used teh following awk script:
#!/bin/awk -f BEGIN { date = "Mon Jun 10 08:24 WITA" print date } /Success rate is 100 percent/ { split($10, rt, "/") print "#IPv4_EBRKDI.1-PE.TRANSIT.BAL=100 percent|" rt[1] " ms" } /BGP state = Established/ { print "#BGP.IPv6=Established" } /FULL/ { print "#OSPF=FULL" }Then you can use this script like this:
Hope that helps!